Basic Information About the Failover Process
A failover occurs when a cluster member is no longer able to perform its designated functions, and another member in the cluster assumes the failed member's responsibilities.
In a Load Sharing configuration, if one cluster member goes down, its connections are distributed among the remaining cluster members. All cluster members in a Load Sharing configuration are synchronized, thus avoiding interrupted connections.
In a High Availability configuration, if currently Active cluster member in a synchronized cluster goes down, another cluster member becomes new Active member and "takes over" the connections of the failed cluster member. If state synchronization is not enabled, then existing connections are closed when failover occurs, although new connections can be opened.
In order to exchange the control information between cluster members (state of each member, state of interfaces, etc), the ClusterXL Cluster Control Protocol is used between cluster members (UDP port 8116). If a certain predetermined time has elapsed and no CCP messages are received from a given cluster member, it is assumed by other cluster members that the given cluster member has failed, it will be declared as Down and a failover might take place. At this point other cluster members automatically assume the responsibilities of the failed one.
 Notes
Notes
- A cluster member may still be operational, but if any of the above checks fail in the cluster, the faulty member initiates the failover because it has determined that it can no longer function as a cluster member.
- More than one cluster member may encounter a problem that will result in a failover event. In cases where all cluster members encounter such problems, ClusterXL will try to choose a single member to continue operating. The state of the chosen member will be reported as Active Attention. This situation lasts until another member fully recovers. For example, if a cross cable connecting the cluster members malfunctions, both members will detect an interface problem. One of them will change its state to theDown, and the other will change its state to Active Attention.
A failover takes place when one of the following occurs on the active cluster member:
- Any critical device (pnote) reports a problem (refer to the output of '
cphaprob -ia list' command). - The machine freezes / crashes (in this case refer to sk31511).
When a failing cluster member recovers:
- In a Load Sharing configuration, all connections are redistributed among all Active members.
- In a High Availability configuration, the recovery method depends on the configured cluster setting.
The options are:- Maintain Current Active Gateway
If one member passes on a control to a lower priority machine, then control will be returned to the higher priority member only if the lower priority member fails. This mode is recommended if all members are equally capable of processing traffic, in order to minimize the number of failover events. - Switch to Higher Priority Gateway
If the lower priority member has control and the higher priority member is restored, then control will be returned to the higher priority member. This mode is recommended if one member is better equipped for handling connections (e.g., has more CPU power, more memory).
- Maintain Current Active Gateway
When a failed cluster member recovers, it will first try to download a policy from one of the other Active cluster members. The assumption is that the other cluster members have a more up-to-date policy. If this does not succeed, the recovering cluster member compares its own local policy to the policy on the Security Management server. If the policy on the Security Management server is more up-to-date than the one on the cluster member, the policy on the Security Management server will be retrieved. If the cluster member does not have a local policy, it retrieves one from the Security Management server. This ensures that all cluster members use the same policy at any given moment.
Troubleshooting the ClusterXL Failovers
To identify the root cause of the ClusterXL failovers:
In this step, we use several methods to understand what is causing the ClusterXL failovers.
- SmartView Tracker - to filter all ClusterXL messages.
- ClusterXL CLI - to understand the current status of the cluster members and the reason for that.
- Analyze the Syslog messages which were generated at the time of the failovers.
Step 1: Using SmartView Tracker:
To facilitate analysis of what happens at the time of the failover, the relevant messages should be exported to a Text file, after modifying the filter:
To export the cluster messages in SmartView Tracker:
- Go to the right-most column "Information"
- Right-click on the name of the column
- Click on "Edit filter"
- Under "Specific" choose "Contains"
- In "Text" type the word "cluster" (do not check any boxes)
- Click on "OK"
- Go to all the empty columns - "Source", "Destination", "Rule", "Curr Rule Number", "Rule Name", "Source Port", "User"
- Right-click on the name of the column
- Click on "Hide Column" (these columns will re-appear after closing and re-opening SmartView Tracker)
- Save all the Cluster messages - go to menu "File" - click on "Export..."
Troubleshooting Method:
Open the exported file you have just saved, look for the ClusterXL messages during the time of the failover and see if there are messages indicating a problem of one or more critical devices (pnotes).
Examples - if you see problems on:
- "Filter" critical device, most likely the policy was unloaded form that member, which caused the failover.
Investigate and understand why the policy was unloaded form that member. - "Interface Active Check" critical device, it means that on one or more interfaces, CCP traffic was not heard on the specified default time configured. This can be a result of networking issues, high latency, physical interface problems, drivers, etc.
Try to eliminate networking issues, drivers, etc. before you change something in the ClusterXL configurations.
Use the ClusterXL Admin Guide for further help on this topic.
Step 2: Using ClusterXL CLI:
There are several commands that can help us to see the ClusterXL status. The most useful commands while a failover took place, are the following:
# cphaprob state# cphaprob -ia list# cphaprob -a if# fw ctl pstat
# cphaprob state:
The following is an example of the output of cphaprob state from Load Sharing Multicast cluster:
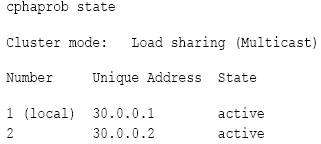
Cluster mode can be:
- Load Sharing (Multicast)
- Load Sharing (Unicast, a.k.a Pivot)
- High Availability New Mode (Primary Up or Active Up)
- High Availability Legacy Mode (Primary Up or Active Up)
- For 3rd-party clustering products: "Service"
The number of the member indicates the Member ID in Load Sharing mode, and the Priority in High Availability mode.
In Load Sharing configuration, all members in a fully functioning cluster should be in 'Active' state.
In High Availability configurations, only one member in a properly functioning cluster must be in 'Active' state, and the others must be in the 'Standby' state.
3d-party clustering products show 'Active'. This is because this command only reports the status of the Full Synchronization process. For Nokia VRRP, this command shows the exact state of the Firewall, but not the cluster member (for example, the member may not be working properly, but the state of the Firewall is active).
Explanations on the ClusterXL members' status:
- Active - everything is OK.
- Active Attention - problem has been detected, but the cluster member still forwarding packets, since it is the only machine in the cluster, or there are no active machines in the cluster.
- Down - one of the critical devices is having problems.
- Ready -
- When cluster members have different versions of Check Point Security Gateway, the members with a new version have the ready state and the members with the previous version have the activestate.
- Before a cluster member becomes active, it sends a message to the rest of the cluster, and then expects to receive confirmations from the other cluster members agreeing that it will becomeactive. In the period of time before it receives the confirmations, the machine is in the ready state.
- When cluster members in versions R70 and higher have different number of CPU cores and/or different number of CoreXL instances, the member with higher number of CPU cores and/or higher number of CoreXL instances will stay in Ready state, until the configuration is set identical on all members.
- Standby - the member is waiting for an active machine to fail in order to start packet forwarding. Applies only in high availability mode.
- Initializing - the cluster member is booting up, and ClusterXL product is already running, but the Security Gateway is not yet ready.
- ClusterXL inactive or machine is down - Local machine cannot hear anything coming from this cluster member.
# cphaprob -ia list
When a critical device (pnote) reports a problem, the cluster member is considered to have failed. Use this command to see the status of the critical devices (pnotes).
There are a number of built-in critical devices, and the administrator can define additional critical devices. The default critical devices are:
- Interface Active Check - monitors the cluster interfaces on the cluster member
- Synchronization - monitors if Full Synchronization completed successfully.
- Filter - monitors if the Security Policy is loaded.
- cphad - monitors the ClusterXL process called 'cphamcset'.
- fwd - monitors the FireWall process called 'fwd'.
For Nokia IP Clustering, the output is the same as for ClusterXL Load Sharing.
For other 3rd-party products, this command produces no output.
Example output shows that the fwd process is down:
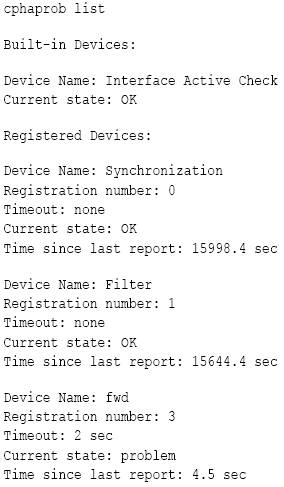
In these cases, check if 'fwd' process is up, using the following commands:
# ps auxw# pidof fwd# cpwd_admin list
If it is not up and running,you need to investigate why.
Check $FWDIR/log/fwd.elg file, try to locate the reason why the fwd process crashes.
Open a case with Check Point support to keep the investigation.
# cphaprob -a if
Use this command to see state of the cluster interfaces.
The output of this command must be identical to the configuration in the cluster object Topology page.
For example:
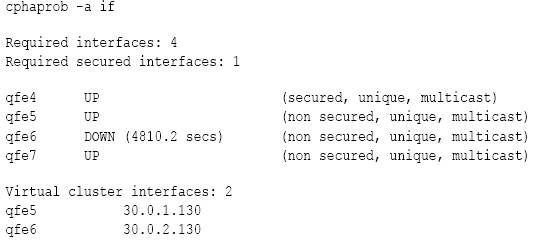
The state of interfaces is critical to operation of ClusterXL. ClusterXL checks the number of working interfaces at boot and sets a value of 'Required interfaces' to the maximum number of 'good' interfaces seen since the last reboot. If the number of working interfaces changes and becomes less, than the 'Required interfaces', ClusterXL initiates failover from this member to other members. The same applies to 'Required secured interfaces', where only the good synchronization interfaces are counted.
For 3rd-party clustering products, except in the case of Nokia IP Clustering, cphaprob -a if should always show cluster Virtual IP addresses.
When a state of an interface is DOWN, it means that the ClusterXL on the local member is not able to receive and/or to transmit CCP packets withing pre-defined timeouts. This may happen when an interface is malfunctioning, is connected to an incorrect subnet, is unable to pick up Multicast Ethernet packets, CCP packets arrive with delay, and so on. The interface may also be able to receive, but not transmit CCP packets, in which case the status field should be checked. The displayed time is the number of seconds that have elapsed since the interface was last able to receive/transmit a CCP packet.
See: "Defining Disconnected Interfaces" section - in the ClusterXL_Admin_Guide.
# fw ctl pstat
Use this command in order to get FW-1 statistics.
When troubleshooting ClusterXL issues, use this command in order to see the Sync network status and statistics.
At the bottom of this command output, are the Sync network statistics.
If that status is in "off", you will see the 'Synchronization' critical device reporting a problem, when running the# cphaprob -i list command.
That means that the Full Sync in the cluster (when a member is booting up or the cluster is configured) did not succeed.
In these cases, refer to the following SK articles:
Step 3: Analyzing Syslog Messages:
In Linux environment, like SPLAT, go to /var/log/messages files, and search for the time of the failover.
In Solaris environments, go to /var/adm/messages and search for the time of the failover.
Look for possible issues that can cause the problem - Link on interfaces going Down, lack of resources like CPU/memory, etc.
When opening Service Request with Check Point support, please attach all these messages to the case, and specify the exact time and date this issue happened, so we can correlate the failover with the logs.
Completing the Procedure
If after following the steps in this guide the failovers are not resolved, open a Service Request with Check Point and provide the following information:
- CPinfo files from all cluster members (make sure to use the latest CPinfo utility installed per sk30567)
- CPinfo file from the MGMT server (make sure to use the latest CPinfo utility installed per sk30567)
- /var/log/messages* from ALL the cluster members --- please supply all the messages files in this directory
- $FWDIR/log/fwd.elg* from ALL the cluster members --- please send all the fwd.elg files in this directory
- $CPDIR/log/cpwd.elg* from ALL the cluster members --- please send all the cpwd.elg files in this directory
- An export of all cluster messages from SmartView Tracker (see Step 1 above)
nice artical
Excellent site